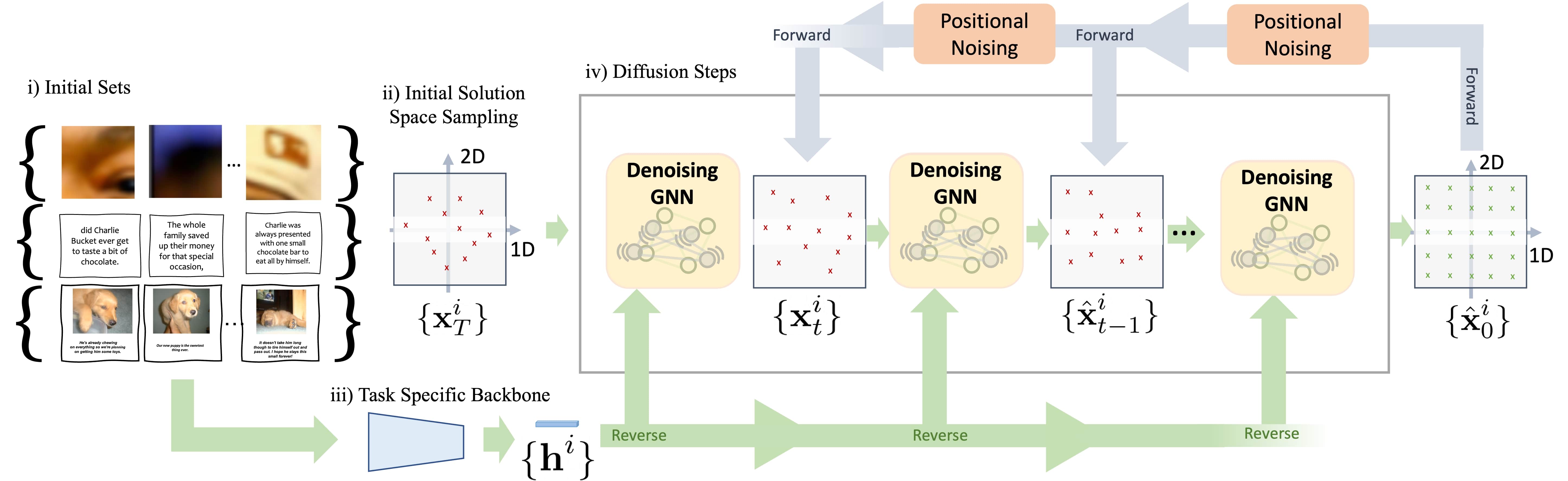
Positional reasoning is the process of ordering unsorted parts contained in a set into a consistent structure. We present Positional Diffusion, a plug-and-play graph formulation with Diffusion Probabilistic Models to address positional reasoning. We use the forward process to map elements’ positions in a set to random positions in a continuous space. Positional Diffusion learns to reverse the noising process and recover the original positions through an Attention-based Graph Neural Network. We conduct extensive experiments with benchmark datasets including two puzzle datasets, three sentence ordering datasets, and one visual storytelling dataset, demonstrating that our method outperforms long-lasting research on puzzle solving with up to +18% compared to the second-best deep learning method, and performs on par against the state-of-the-art methods on sentence ordering and visual storytelling. Our work highlights the suitability of diffusion models for ordering problems and proposes a novel formulation and method for solving various ordering tasks.
Datasets
Puzzles
Text
VIST
- VIST dataset: https://visionandlanguage.net/VIST/
- Json file: https://visionandlanguage.net/VIST/json_files/story-in-sequence/SIS-with-labels.tar.gz
- Use our script to download training and test images, given the raw json file for VIST
Environment
- We provide the environment definition in
singularity/build/conda_env.yaml - Singularity image is also available at [WIP]
- Requirements:
```
- pytorch==1.12.1
- cudatoolkit<=11.3.10
- pyg
- einops
- black
- pre-commit
- pytorch-lightning<1.8
- pip
- matplotlib
- wandb
- transformers
- timm
- kornia ```
Training
Puzzles
Training script for puzzle:
- Choose between two datsets: wikiart, celeba
- Train model on all puzzle sizes: 6,8,10,12
- At inference, choose between zero-center sampling (
--noise_weight 0) or gaussian sampling (--noise_weight 1)
python puzzle_diff/train_script.py -dataset [wikiart,celeba] -puzzle_sizes 6,8,10,12 -inference_ratio 10 -sampling DDIM -gpu 1 -batch_size 8 -steps 300 -num_workers 6 --noise_weight [0,1] --predict_xstart True




TEXT
Training script for Text:
- Choose between three datasets: roc,wiki,nips
python puzzle_diff/train_text.py -dataset roc -inference_ratio 10 -sampling DDIM -gpus 2 -batch_size 16 -steps 100 -num_workers 6 --predict_xstart True
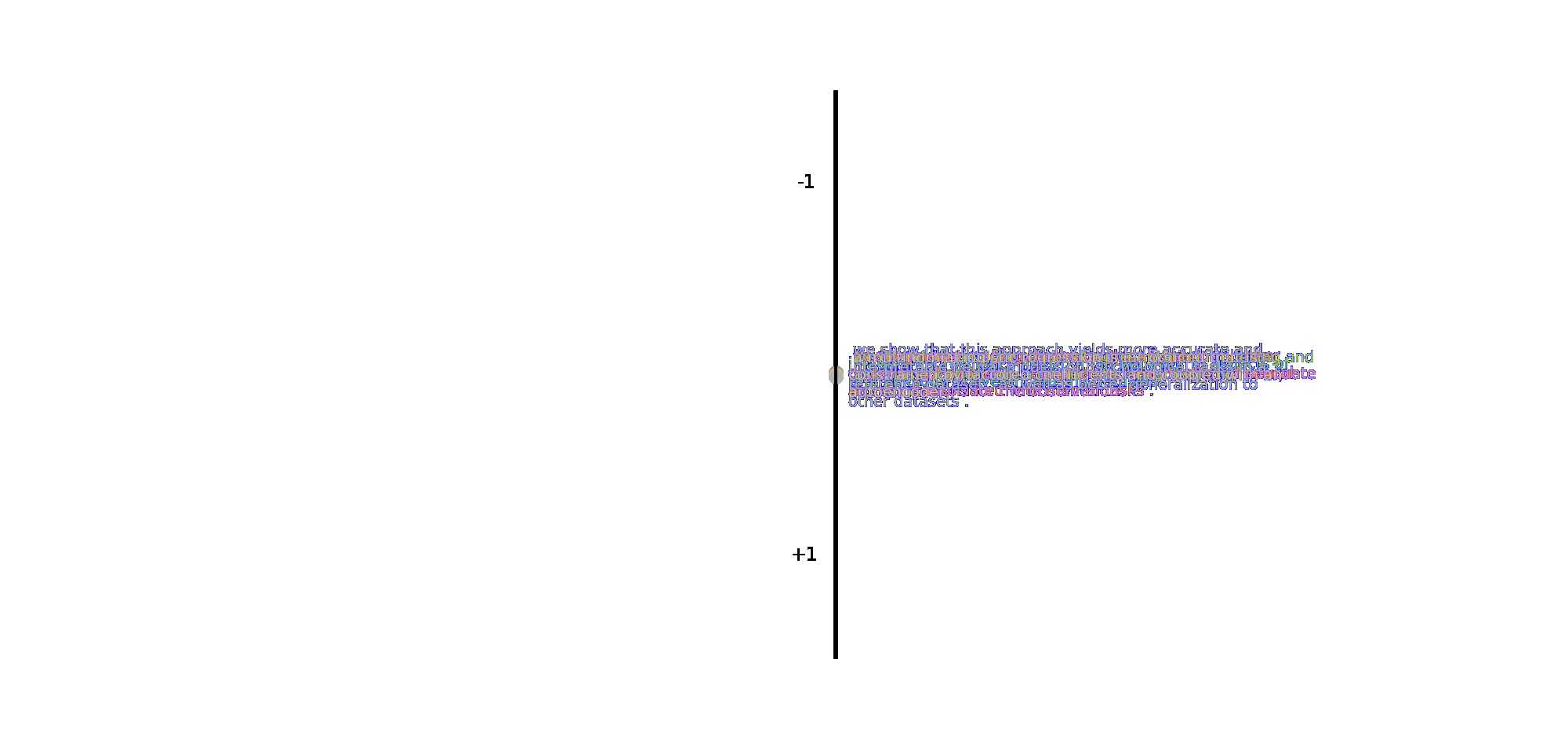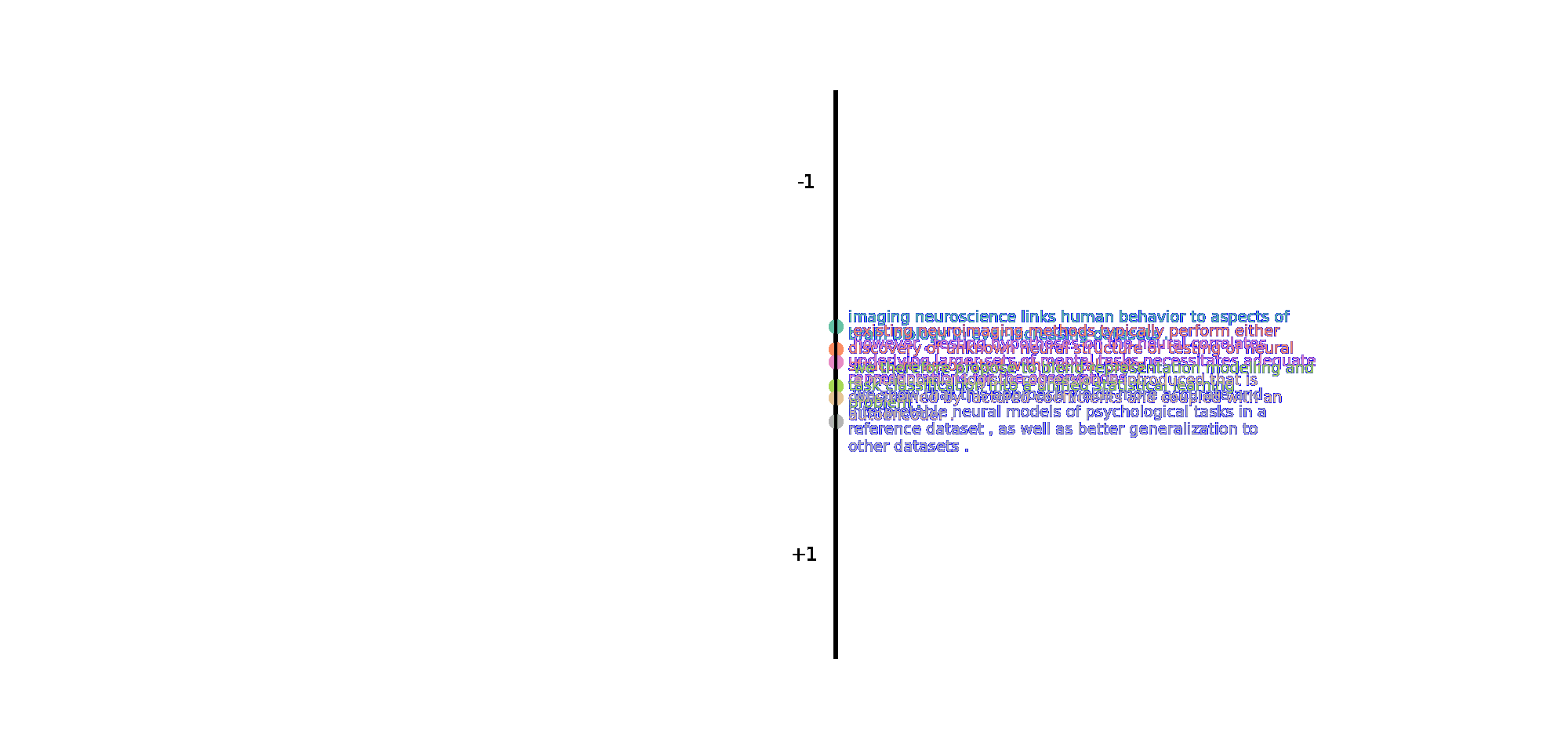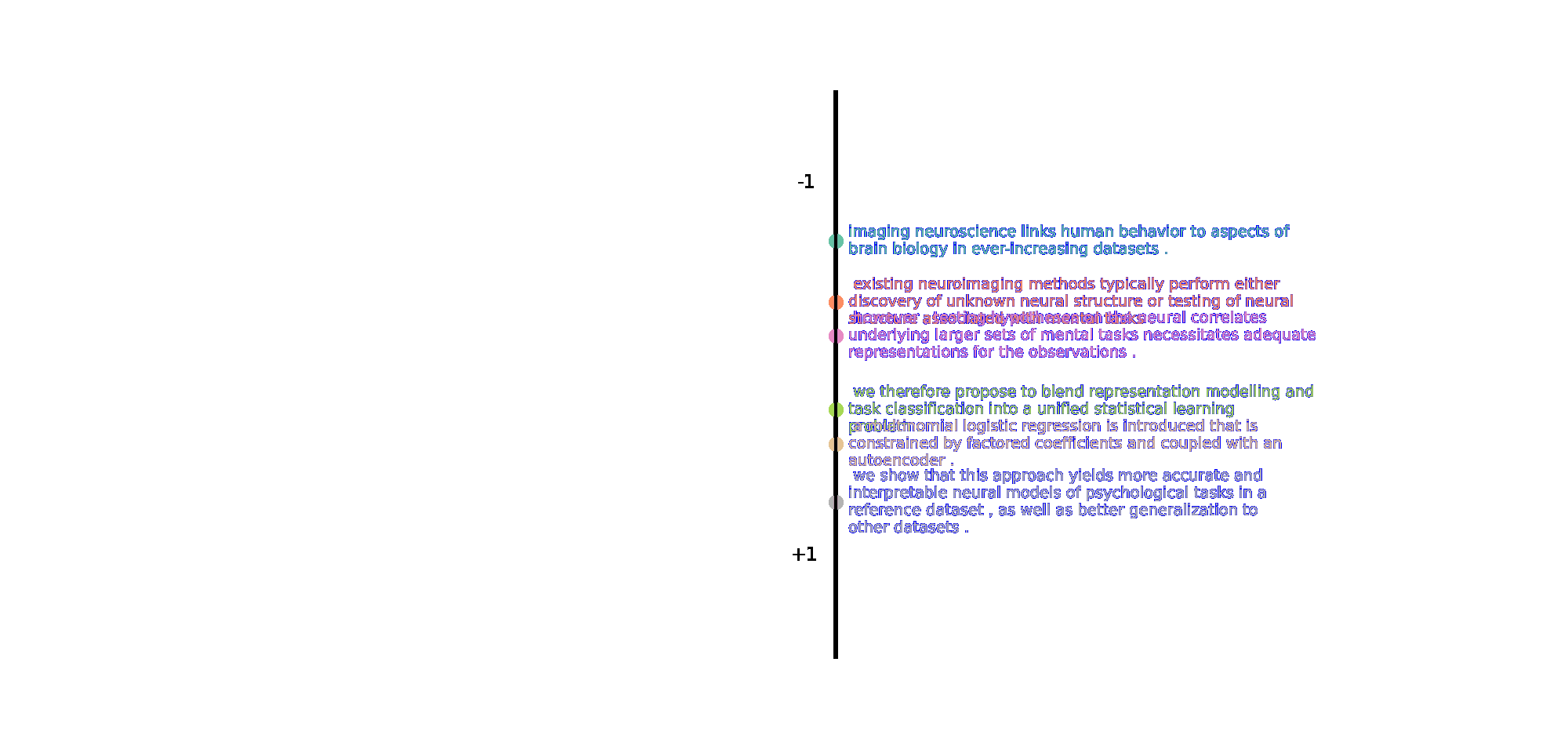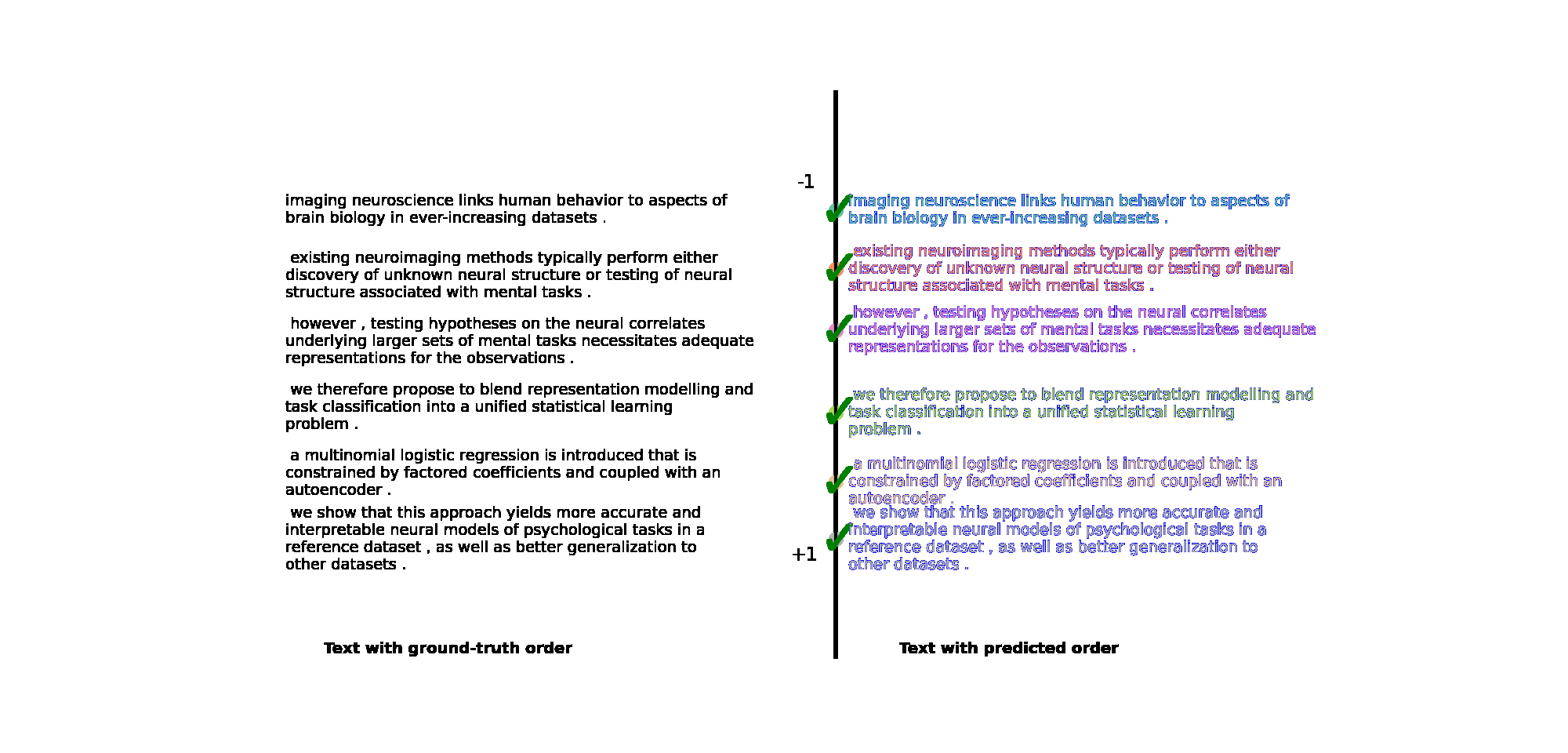
VIST
Training script for VIST:
python puzzle_diff/train_vist.py -dataset sind -inference_ratio 10 -sampling DDIM -gpus 1 -batch_size 8 -steps 100 -num_workers 6 --predict_xstart True
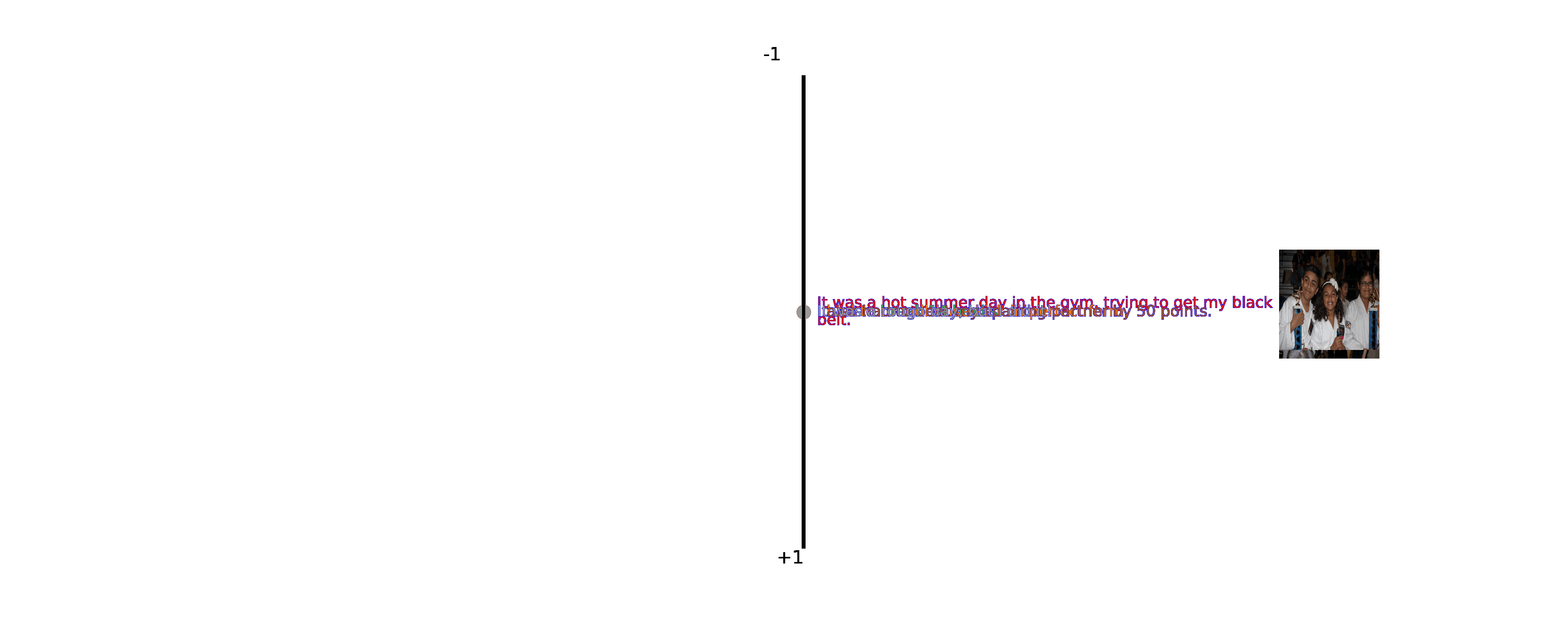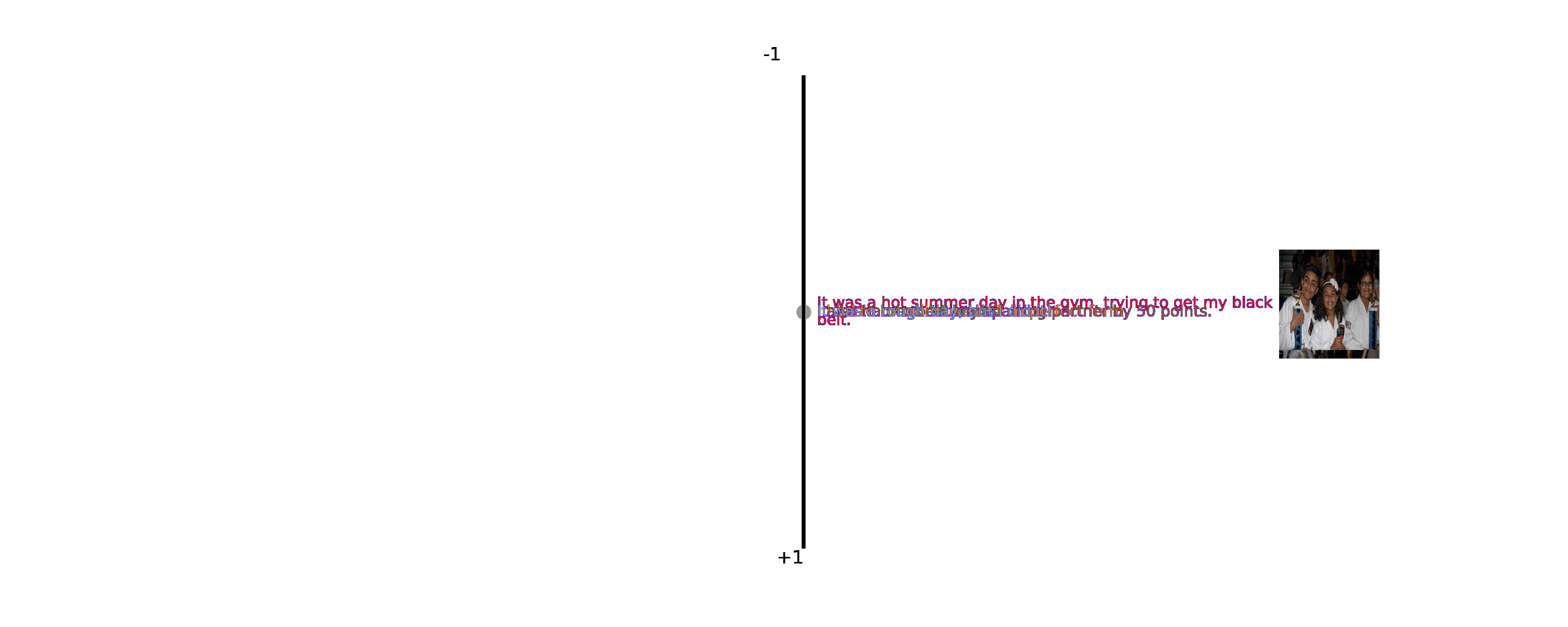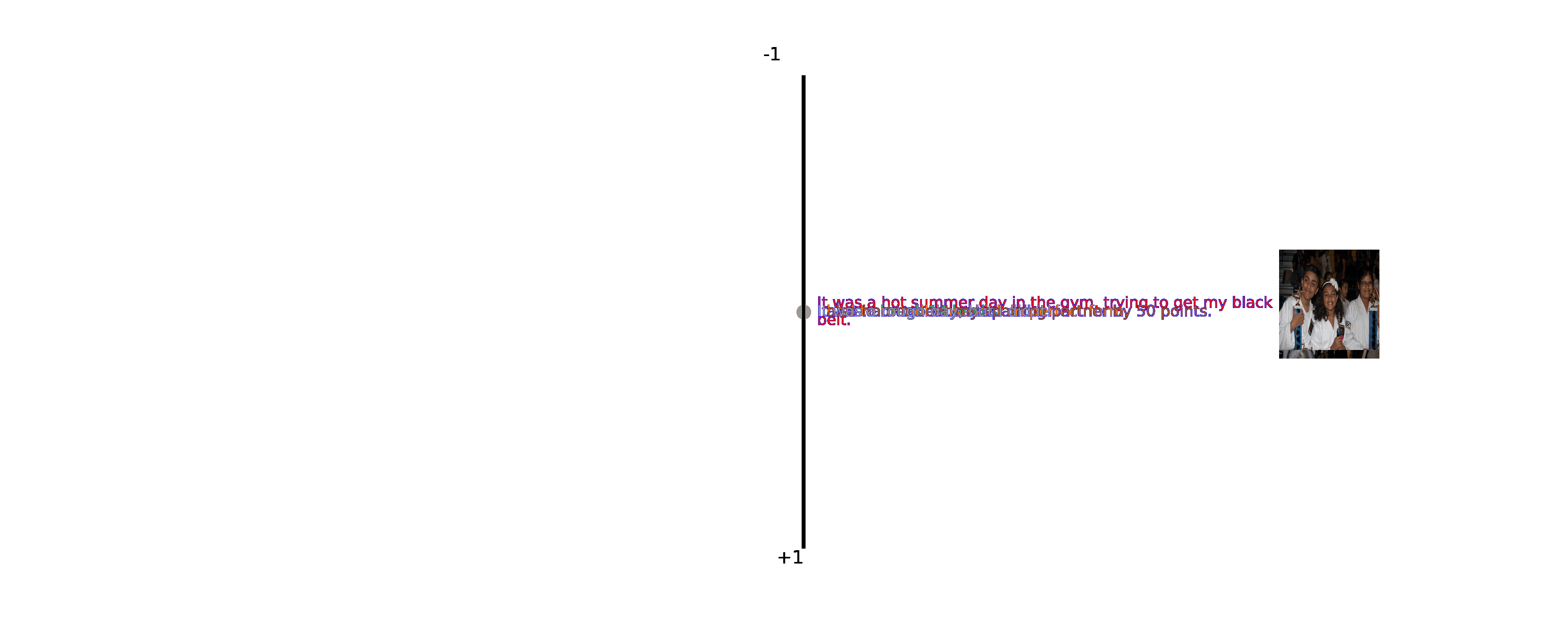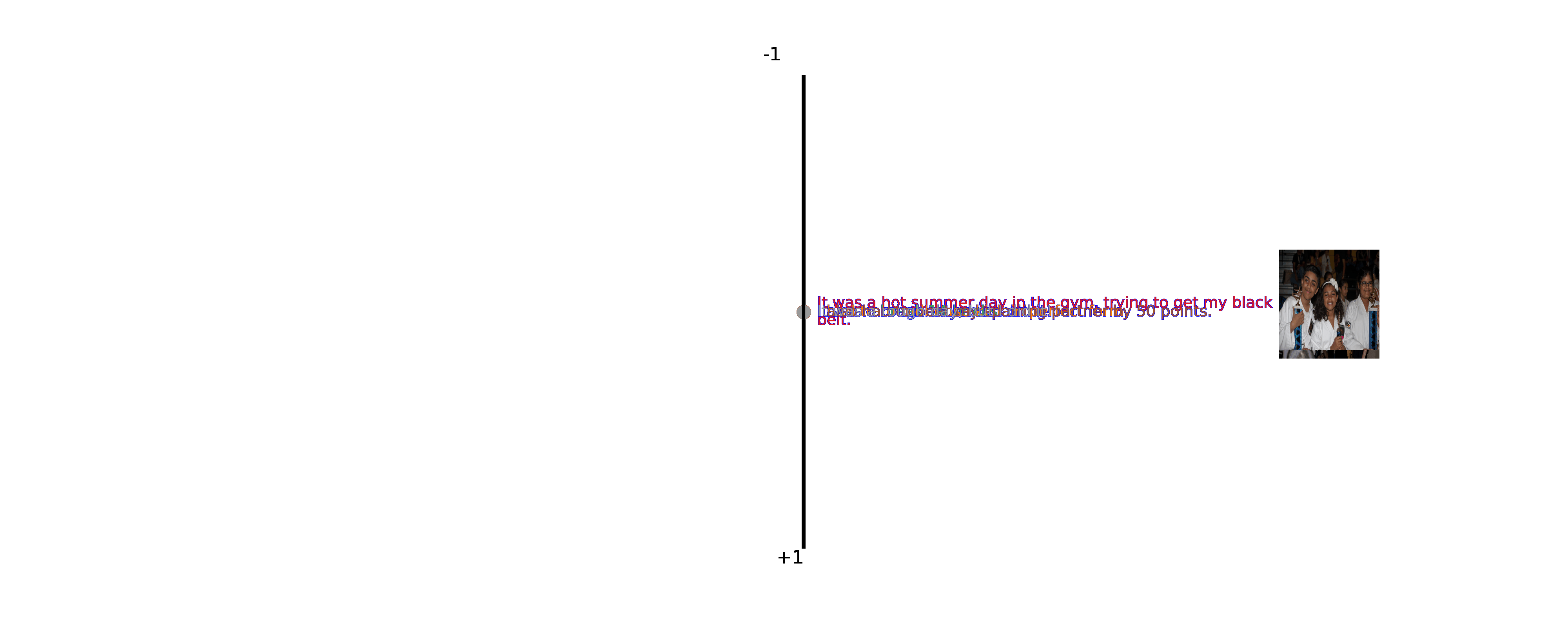
Additional parameters
Given the path for a model checkpoint /path/to/ckpt, specify the path for continuing training, as:
... --checkpoint_path /path/to/ckpt
Pretrained models
We plan to release our pre-trained models for all tasks.
Cite us!
@misc{giuliari2023positional,
title={Positional Diffusion: Ordering Unordered Sets with Diffusion Probabilistic Models},
author={Francesco Giuliari and Gianluca Scarpellini and Stuart James and Yiming Wang and Alessio {Del Bue}},
year={2023},
eprint={2303.11120},
archivePrefix={arXiv},
primaryClass={cs.CV}
}