Lifting Monocular Events to 3D Human Poses

![]()
Gianluca Scarpellini Pietro Morerio Alessio Del Bue
Table of contents
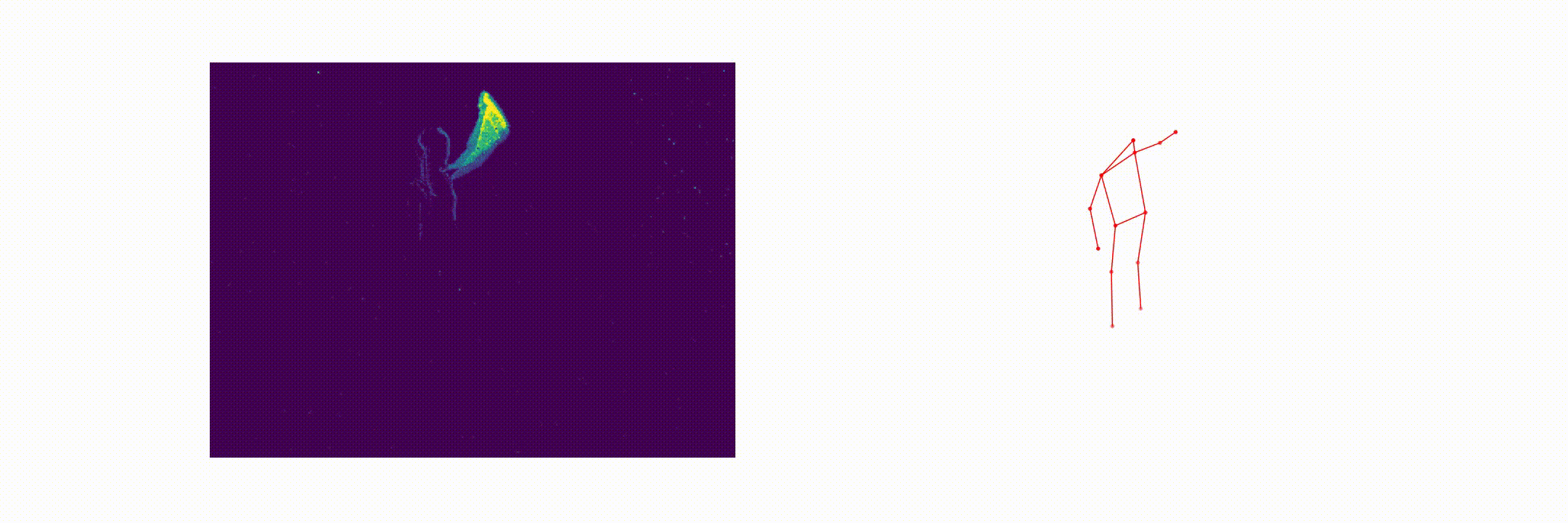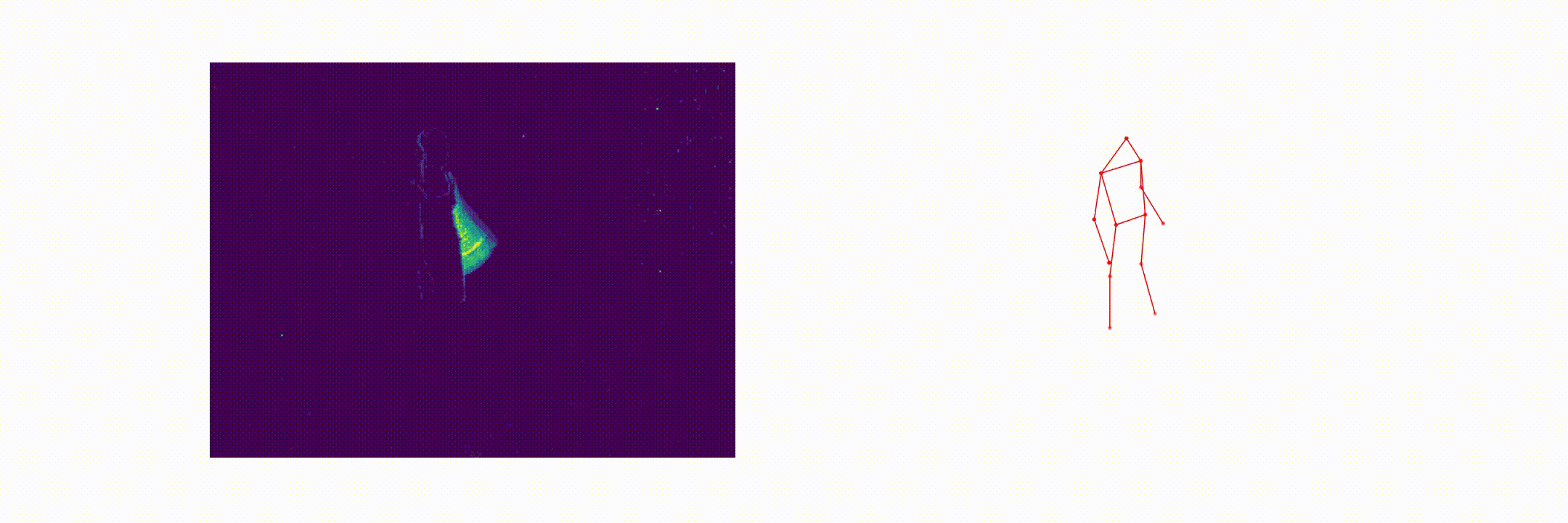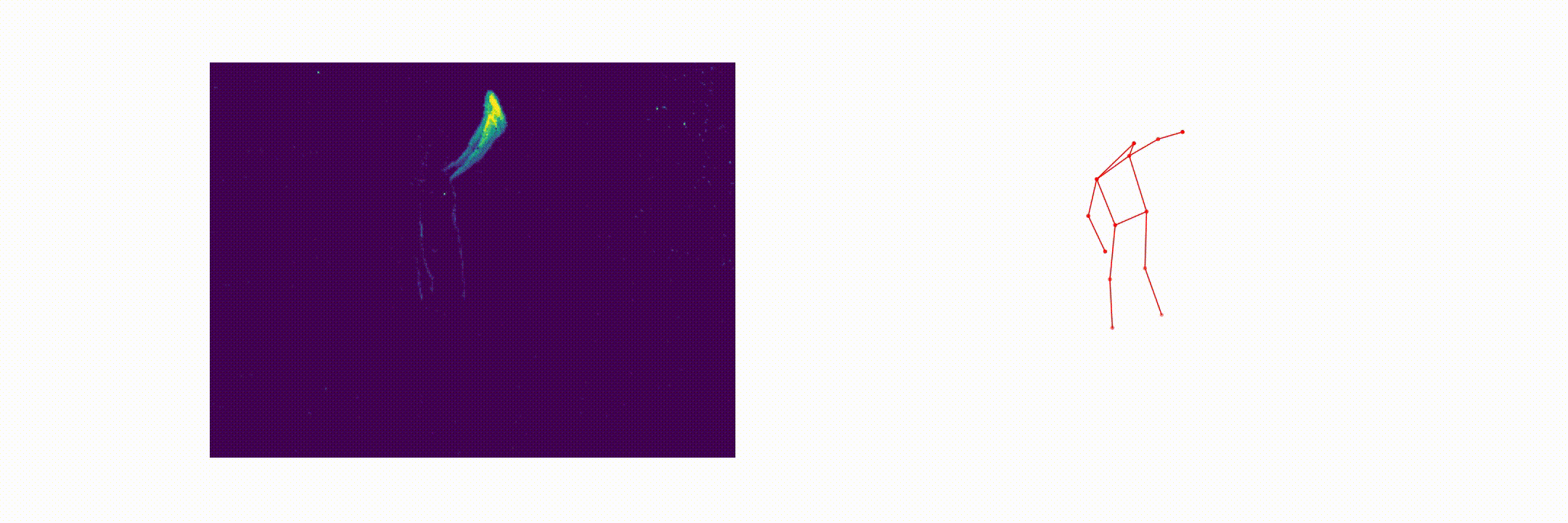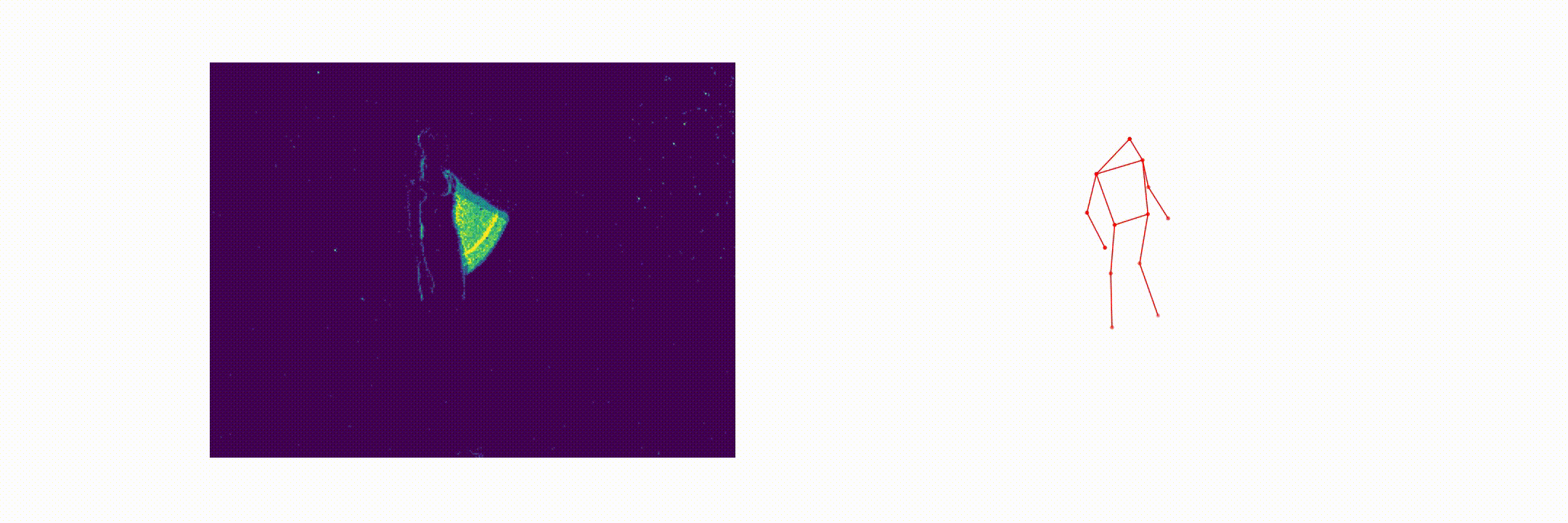
Abstract
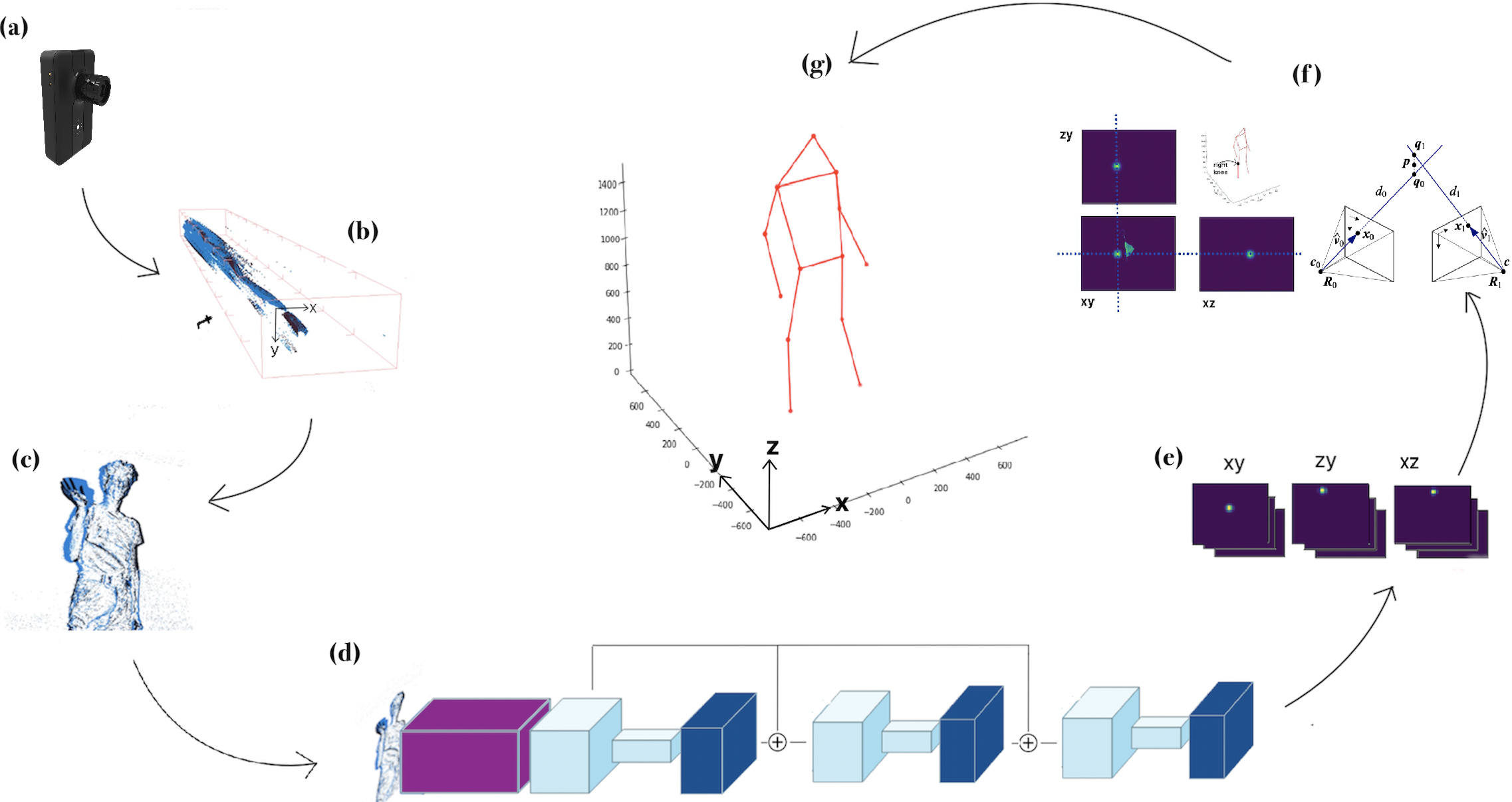
This paper presents a novel 3D human pose estimation approach using a single stream of asynchronous events as input. Most of the state-of-the-art approaches solve this task with RGB cameras, however struggling when subjects are moving fast. On the other hand, event-based 3D pose estimation benefits from the advantages of event-cameras [2], especially their efficiency and robustness to appearance changes. Yet, finding human poses in asynchronous events is in general more challenging than standard RGB pose estimation, since little or no events are triggered in static scenes. Here we propose the first learning-based method for 3D human pose from a single stream of events. Our method consists of two steps. First, we process the event-camera stream to predict three orthogonal heatmaps per joint; each heatmap is the projection of of the joint onto one orthogonal plane. Next, we fuse the sets of heatmaps to estimate 3D localization of the body joints. As a further contribution, we make available a new, challenging dataset for event-based human pose estimation by simulating events from the RGB Human3.6m dataset. Experiments demonstrate that our method achieves solid accuracy, narrowing the performance gap between standard RGB and event-based vision.
- Code (implemented with pytorch-lightning [1])
- Documentation
- Paper
Event-Human3.6m
The generation pipeline details and code are released at https://github.com/IIT-PAVIS/lifting_events_to_3d_hpe/tree/master/scripts/h3m.
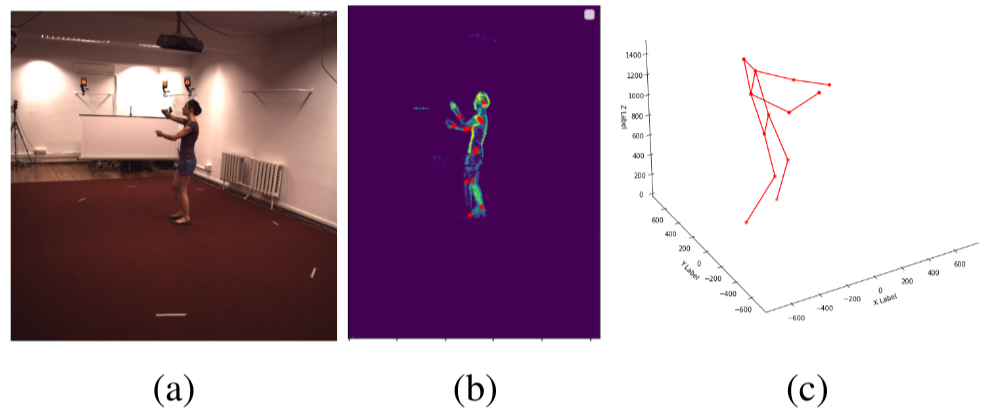
Method
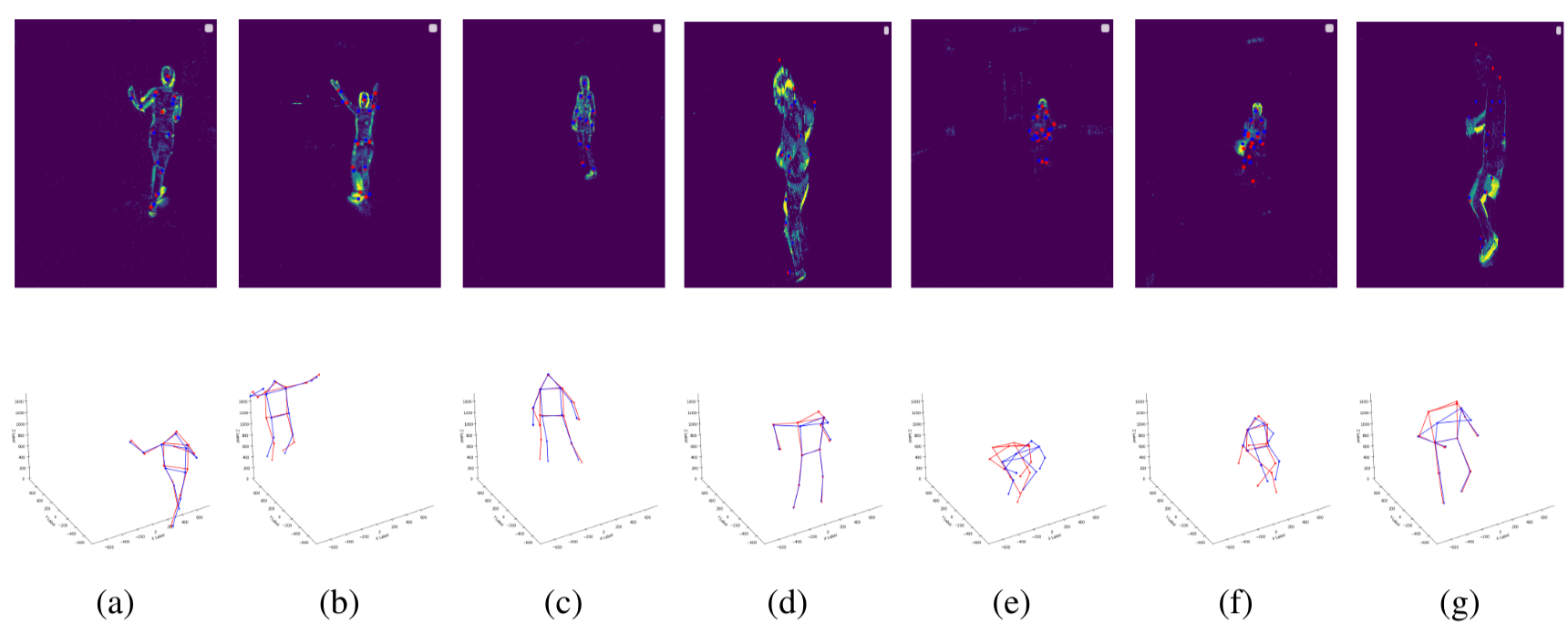
Results
DHP19
| Method | input | MPJPE(mm) |
|---|---|---|
| Calabrese et al. [9] | stereo | 79.63 |
| Constant-count – stage 3 | monocular | 92.09 |
| Voxel-grid – stage 3 | monocular | 95.51 |
| Constant-count – stage 1 | monocular | 96.69 |
| Voxel-grid – stage 1 | monocular | 105.24 |
Event-H3m
| Method | input | MPJPE(mm) |
|---|---|---|
| Metha et al. 2018 [3] | RGB | 80.50 |
| Kanazawa et al. 2018 [4] | RGB | 88.00 |
| Nibali et al. 2018 [5] | RGB | 57.00 |
| Pavlakos et al. 2017 [6] | RGB | 71.90 |
| Luvizon et al. 2018 [7] | RGB | 53.20 |
| Cheng et al. 2020 [8] | RGB | 40.10 |
| Spatio-temporal voxel-grid | Events | 119.18 |
| Constant-count | Events | 116.40 |
References
[1] Falcon, WA and .al (2019). PyTorch Lightning GitHub. Note: https://github.com/PyTorchLightning/pytorch-lightning
[2] Gallego, Guillermo, Tobi Delbruck, Garrick Michael Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, et al. 2020. “Event-Based Vision: A Survey.” IEEE Transactions on Pattern Analysis and Machine Intelligence. Institute of Electrical and Electronics Engineers (IEEE), 1. http://dx.doi.org/10.1109/TPAMI.2020.3008413
[3] Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko,Helge Rhodin, Mo-Hammad Shafiei, Hans-Peter Seidel,Weipeng Xu, Dan Casas, Christian Theobalt, and Rey JuanCarlos. VNect: Real-time 3D Human Pose Estimation witha Single RGB Camera. Technical report, 2017. 2, 3, 5, 6
[4] Angjoo Kanazawa, Michael J. Black, David W. Jacobs, andJitendra Malik. End-to-end recovery of human shape andpose. In2018 IEEE/CVF Conference on Computer Visionand Pattern Recognition. IEEE, jun 2018. 6
[5] Aiden Nibali, Zhen He, Stuart Morgan, and Luke Pren-dergast.3D Human Pose Estimation with 2D MarginalHeatmaps. 6 2018
[6] Georgios Pavlakos, Xiaowei Zhou, Konstantinos G. Derpa-nis, and Kostas Daniilidis. Coarse-to-fine volumetric predic-tion for single-image 3d human pose. In2017 IEEE Confer-ence on Computer Vision and Pattern Recognition (CVPR),page nil, 7 2017.
[7] Diogo C. Luvizon, David Picard, and Hedi Tabia. 2d/3d poseestimation and action recognition using multitask deep learn-ing. InThe IEEE Conference on Computer Vision and Pat-tern Recognition (CVPR), June 2018.
[8] Yu Cheng, Bo Yang, Bo Wang, and Robby T. Tan. 3d humanpose estimation using spatio-temporal networks with explicitocclusion training.Proceedings of the AAAI Conference onArtificial Intelligence, 34(07):1
[9] Enrico Calabrese, Gemma Taverni, Christopher Awai East-hope, Sophie Skriabine, Federico Corradi, Luca Longinotti,Kynan Eng, and Tobi Delbruck. Dhp19: Dynamic visionsensor 3d human pose dataset. InThe IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR) Work-shops, June 2019.